Documentação Viva
O que é Documentação Viva?
O Serenity BDD é mais do que uma biblioteca que gera relatórios de teste. Ou seja, embora você possa usar o Serenity BDD para produzir ótimos relatórios de teste, o verdadeiro objetivo do Serenity BDD é produzir documentação viva para o seu produto.
Mas o que queremos dizer com "documentação viva"? Documentação Viva é um conceito que vem do mundo do Desenvolvimento Orientado a Comportamento (BDD). Está intimamente relacionado à ideia de Especificações Executáveis. A documentação viva é, como o nome sugere, tanto documentação quanto viva.
- É documentação, porque descreve como uma aplicação funciona e quais regras de negócio ela aplica, de uma forma que usuários comuns podem entender. Documentação viva bem escrita pode ser usada por novos membros da equipe para entender o que um produto faz e como funciona. Pode ser entregue a uma equipe de manutenção quando a aplicação entra em produção, ou pode ser usada como evidência para auditores para mostrar que a aplicação respeita as regras e regulamentos relevantes.
- É viva, porque é gerada pela suíte de testes automatizados e, portanto, por definição está sempre atualizada.
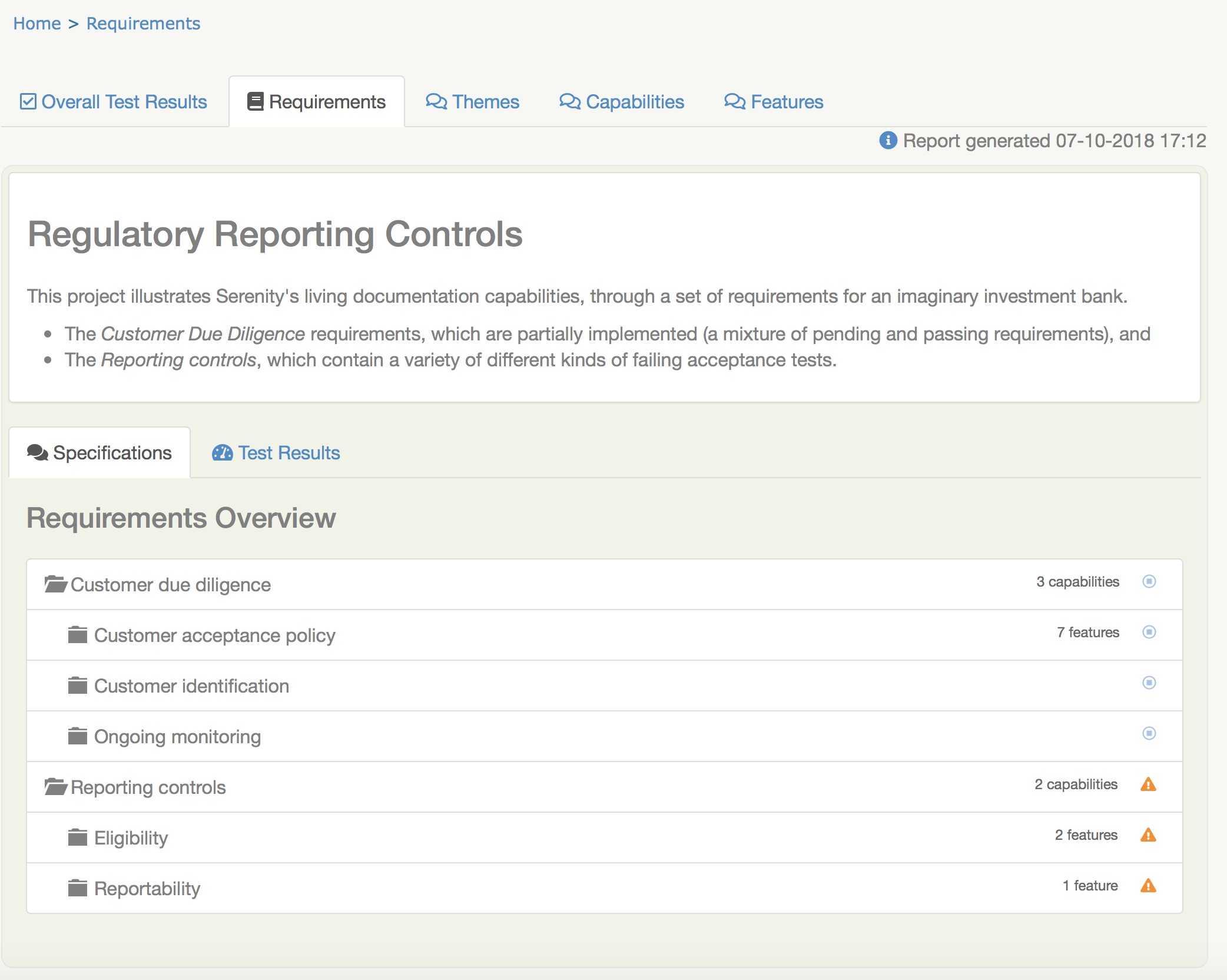
Em um relatório do Serenity BDD, você pode encontrar a Documentação Viva na aba Requirements.
Aba Requirements
Documentação Viva e Relatórios de Teste
A Documentação Viva não deve ser confundida com relatórios de teste convencionais. Existem várias diferenças importantes, e entender essas diferenças facilita escrever documentação viva de boa qualidade.
Momento
Os relatórios de teste convencionais são projetados e gerados relativamente tarde no processo de desenvolvimento, normalmente depois que as funcionalidades foram entregues e os testes automatizados escritos. Os testadores frequentemente começam o trabalho preparatório nos casos de teste assim que as especificações ou histórias de usuário são finalizadas, mas os relatórios de teste ainda são uma atividade que acontece mais tarde do que mais cedo no processo de desenvolvimento.
Para uma equipe que pratica BDD, por outro lado, o trabalho na Documentação Viva começa muito mais cedo. Equipes que praticam BDD trabalharão junto com product owners para definir critérios de aceitação para as histórias a serem desenvolvidas, e esses critérios de aceitação formarão a base para os testes de aceitação automatizados e para a documentação viva que é gerada a cada build.
Autores
Relatórios de Teste são responsabilidade do QA; testadores são geralmente os que projetam a estrutura do relatório (se algum design é feito) e geram os relatórios de teste.
A Documentação Viva, por outro lado, é escrita colaborativamente por muitos atores diferentes: BAs, desenvolvedores, testadores e product owners, todos desempenham papéis fundamentais no processo de descoberta de requisitos do BDD, e ajudam, juntos, a expressar as necessidades de negócio em uma forma que pode ser executada como testes de aceitação automatizados.
Público e Linguagem
Testadores também são os principais consumidores de relatórios de teste. Em muitos projetos, outros membros da equipe só verão resumos ou visões gerais dos relatórios de teste.
A Documentação Viva é para toda a equipe, incluindo product owners, stakeholders e usuários envolvidos no projeto. Ela descreve o que a aplicação deve fazer antes que uma funcionalidade seja implementada (na forma de cenários pendentes), e demonstra (e fornece evidências) que a funcionalidade implementada se comporta como esperado (na forma de cenários passando). Por essa razão, os cenários de documentação viva precisam ser escritos em termos de negócio, de uma forma que seja facilmente compreensível por não-testadores.
Propósito e escopo
Produzido por testadores e para testadores, um relatório de teste naturalmente tem um foco muito forte em testes. A ênfase está principalmente em saber se um teste passa ou falha, e, em um nível mais alto, saber que proporção de testes passa ou falha.
A Documentação Viva é mais como um manual do usuário ilustrado muito detalhado. O foco é descrever o que a aplicação faz, em termos de negócio.
Por exemplo, um cenário em um relatório de teste pode estar interessado em verificar se todos os países aparecem em uma lista suspensa de países em uma página de registro de usuário. Um cenário aparecendo em um relatório de documentação viva estaria mais interessado em descrever o processo de registro de usuário como um todo, e demonstrar como funciona para diferentes tipos de usuários, e quais restrições ou limitações de negócio se aplicam à escolha de países.
Essas diferenças podem ser resumidas na seguinte tabela:
| Relatórios de Teste | Documentação Viva |
|---|---|
| Produzido após o desenvolvimento estar concluído | Escrito antes do desenvolvimento começar |
| Escrito por testadores | Escrito colaborativamente por toda a equipe |
| Escrito principalmente para testadores | Para toda a equipe e além |
| Relata testes passando e falhando | Descreve exemplos funcionais de funcionalidade |
Documentação Viva e outros tipos de testes
A Documentação Viva é projetada para funcionar junto com testes unitários e de integração de nível mais baixo para fornecer um alto grau de confiança na qualidade da aplicação. A documentação viva geralmente se concentrará em exemplos-chave de caminhos positivos e negativos através da aplicação, e deixará os testes mais exaustivos para as camadas de teste unitário.
Em ambientes altamente regulados, por outro lado, a documentação viva frequentemente será mais exaustiva e detalhada, pois pode ser usada para auditorias ou relatórios regulatórios.
No Serenity, a documentação viva pode ser "em camadas", de modo que os detalhes mais importantes sejam apresentados primeiro, e os cenários mais exaustivos apresentados mais abaixo.
No coração deste relatório está a aba Requirements. Vamos ver o que você encontrará lá.
A visualização de Requisitos
A visualização de requisitos do Serenity é uma parte central da abordagem de relatórios do Serenity, e entender como funciona é fundamental para produzir uma ótima documentação viva. A documentação viva do Serenity vai muito além dos relatórios de teste tradicionais: em equipes BDD maduras trabalhando em grandes organizações, stakeholders regularmente usam a documentação viva produzida pelo Serenity não apenas para validar e documentar novos releases, mas também para explicar e documentar como o sistema funciona.
Vamos examinar as várias partes deste relatório, para entender melhor como você pode configurá-los em seus próprios projetos.
A Hierarquia de Requisitos
No Serenity, os requisitos são organizados em uma hierarquia. Você pode ver essa hierarquia na estrutura de árvore na parte inferior da aba Requirements mostrada em Um relatório de teste gerado pelo Serenity.
Existem algumas ideias de como você pode organizar essa hierarquia no final deste capítulo. Você pode dividir seus requisitos por capacidades de alto nível até funcionalidades mais granulares, ou pode fazer mais sentido organizar as coisas em termos de alguma funcionalidade de negócio transversal.
Em todos os casos, a hierarquia de requisitos é implementada como uma estrutura de diretórios aninhados (para Cucumber ou JBehave) ou como uma estrutura de pacotes (para JUnit).
A hierarquia de Requisitos pode ter qualquer profundidade, embora possa ser confuso se diferentes ramos tiverem profundidades diferentes. No nível mais baixo estão os arquivos de feature (para Cucumber), arquivos de story (para JBehave) ou classes de teste (para JUnit). Os diretórios que contêm esses arquivos representam os requisitos de nível mais alto.
Você pode ter uma ideia da estrutura completa de diretórios (no diretório src/test/features) para o projeto mostrado em Um relatório de teste gerado pelo Serenity aqui:
├── customer_due_diligence
│ ├── customer_acceptance_policy
│ │ ├── business_activities.feature
│ │ ├── country_risk_ratings.feature
│ │ ├── customer_risk_profiles.feature
│ │ ├── enhanced_due_diligence.feature
│ │ ├── non-face-to-face-customers.feature
│ │ ├── pep.feature
│ │ ├── readme.md
│ │ └── standard_due_diligence.feature
│ ├── customer_identification
│ │ └── readme.md
│ ├── ongoing_monitoring
│ │ └── readme.md
│ └── readme.md
├── readme.md
└── reporting_controls
├── eligibility
│ ├── cftc_eligibility.feature
│ ├── mifid2_eligibility.feature
│ └── readme.md
├── readme.md
└── reportability
├── readme.md
└── reportable_state.feature
Se você expandir os nós da visualização em árvore de requisitos, obterá uma estrutura semelhante na aba Requirements (veja Uma árvore de requisitos expandida).
Uma árvore de requisitos expandida
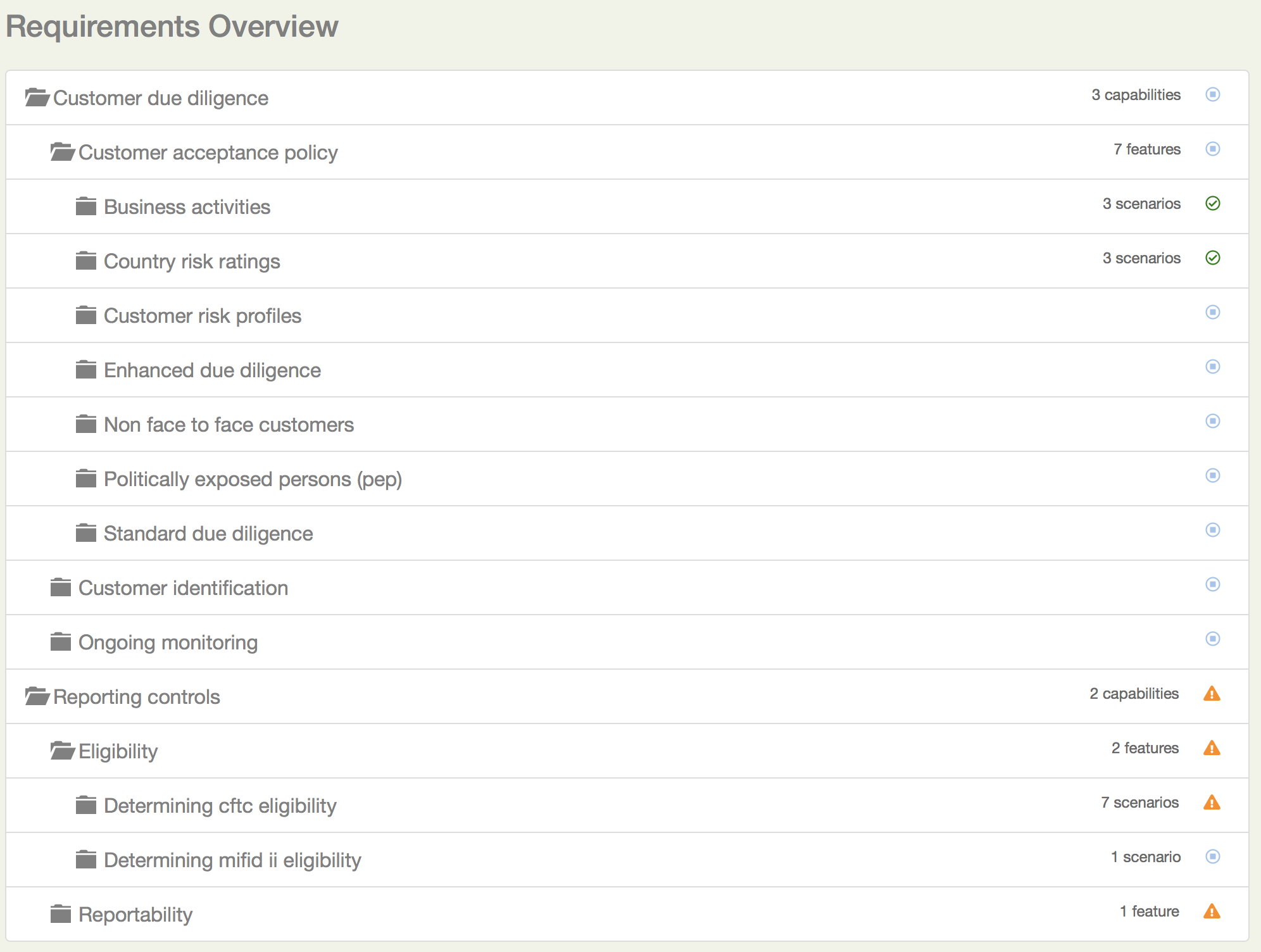
A visualização em árvore também fornece algumas informações extras úteis. O pequeno ícone no lado direito da linha de requisitos indica o resultado geral de quaisquer testes executados (requisitos sem testes implementados são marcados como pendentes). A árvore também indica quantos sub-requisitos existem abaixo de cada requisito.
A descrição do Requisito
A descrição do requisito é a primeira coisa que você vê em um relatório típico de documentação viva - você pode vê-la abaixo na caixa branca no topo do relatório:
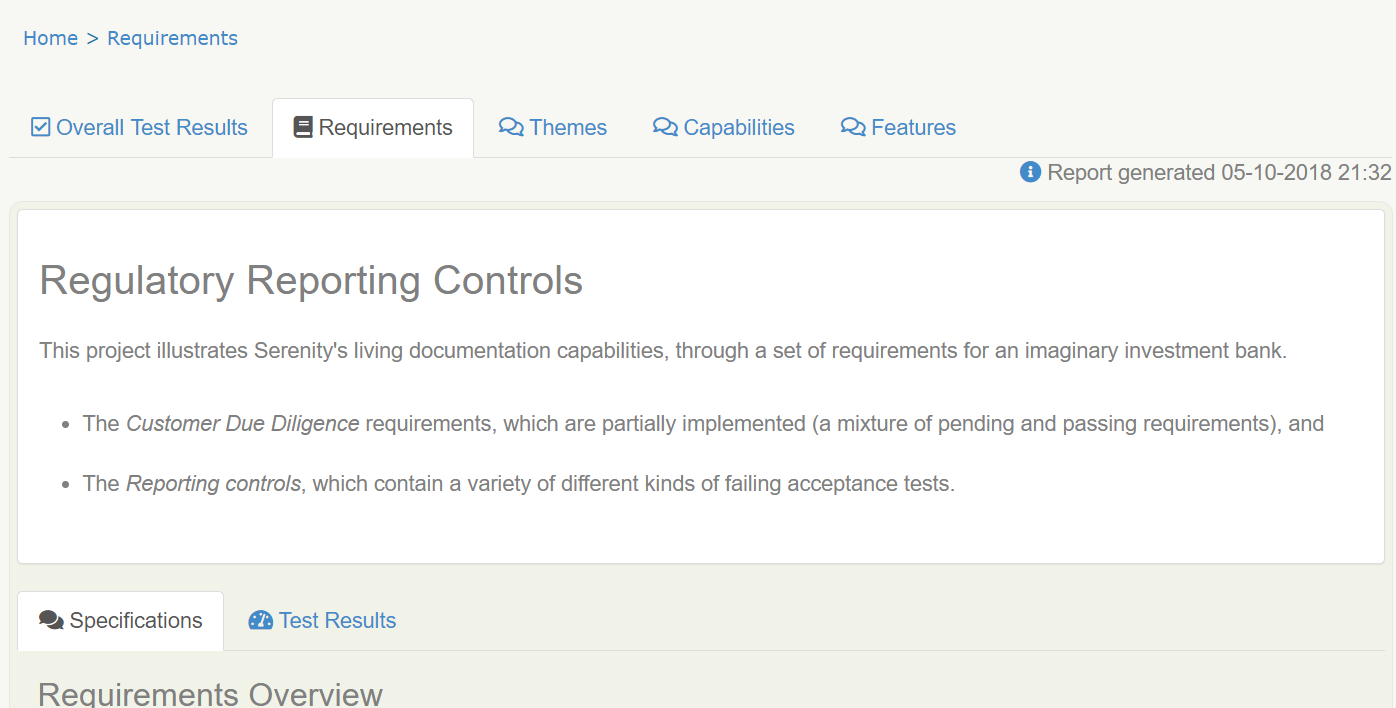
Este texto é um pouco como uma introdução a um livro ou a um capítulo de um livro - deve apresentar a aplicação ou funcionalidade de alto nível que é descrita em detalhes no resto do relatório.
Você pode adicionar este texto introdutório em qualquer nível da sua hierarquia de requisitos adicionando um arquivo readme.md no nível apropriado da sua hierarquia de requisitos. Um conjunto bem documentado de documentação viva terá arquivos readme.md em cada nível da hierarquia, para explicar o propósito e o contexto de cada área funcional na aplicação. Você pode ver esses arquivos na estrutura de diretórios que examinamos na seção anterior.
Markdown (https://daringfireball.net/projects/markdown/) é um formato leve e conveniente que você pode usar para tornar sua documentação viva mais legível. O markdown usado no relatório mostrado acima é assim:
## Controles de Relatórios Regulatórios
Este projeto ilustra as capacidades de documentação viva do Serenity, através de um conjunto de requisitos para um banco de investimento imaginário.
* Os requisitos de _Customer Due Diligence_, que estão parcialmente implementados (uma mistura de requisitos pendentes e passando), e
* Os _Controles de Relatórios_, que contêm uma variedade de testes de aceitação falhando.
Para qualquer readme.md em um diretório de requisitos aninhado (então qualquer arquivo readme.md que não seja o de nível superior), a primeira linha deve conter o nome do requisito. Um exemplo para a capacidade Customer Due Diligence é mostrado abaixo:
## Customer Due Diligence
Os bancos são obrigados a "ter políticas, práticas e procedimentos adequados que promovam altos padrões éticos e profissionais e impeçam que o banco seja usado, intencionalmente ou não, por elementos criminosos".
Certos elementos-chave devem ser incluídos pelos bancos no design de programas KYC. Tais elementos essenciais devem começar a partir dos procedimentos de gerenciamento de risco e controle dos bancos e devem incluir
1) política de aceitação de clientes,
2) identificação de clientes, e
3) monitoramento contínuo de contas de alto risco
Adicionando imagens à descrição do requisito
Você também pode incluir imagens nos arquivos readme.md. Por padrão, o Serenity copiará quaisquer arquivos no diretório src/test/resources/assets para o diretório target/site/serenity/assets quando gerar os relatórios.
Você pode colocar quaisquer imagens que deseja incluir na sua documentação viva aqui, e então referenciá-las usando a sintaxe de imagem do Markdown, assim:

Esta imagem então apareceria nos seus relatórios, como ilustrado aqui:
Se você precisar substituir a localização do diretório assets, pode fazê-lo usando a propriedade report.assets.directory, como mostrado aqui:
report.assets.directory=src/test/resources/my-special-resources
Observe que o diretório de destino no diretório target/site/serenity sempre será chamado assets.
A aba Resultados dos Testes
A aba Resultados dos Testes (mostrada abaixo) informa sobre os testes de aceitação que foram executados para este conjunto de requisitos. Tanto os testes automatizados quanto manuais aparecem no gráfico de rosca de resumo e na tabela (os resultados manuais são da mesma cor que os resultados automatizados equivalentes, mas em um tom mais claro).
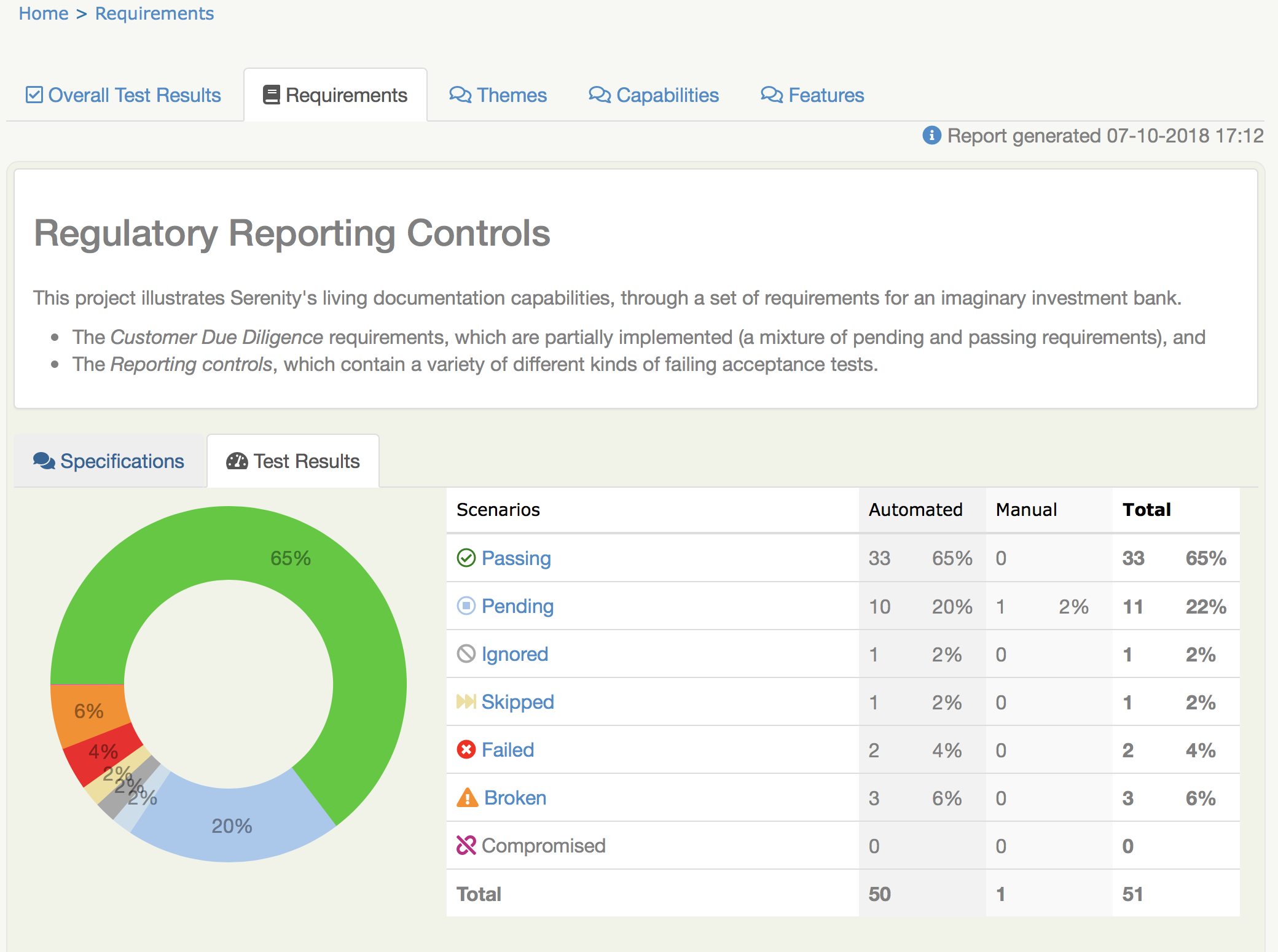
Você também pode encontrar a lista completa de resultados de testes automatizados e manuais na parte inferior da tela.
Cobertura Funcional
A seção de Cobertura Funcional mostra os resultados dos testes divididos por área funcional.
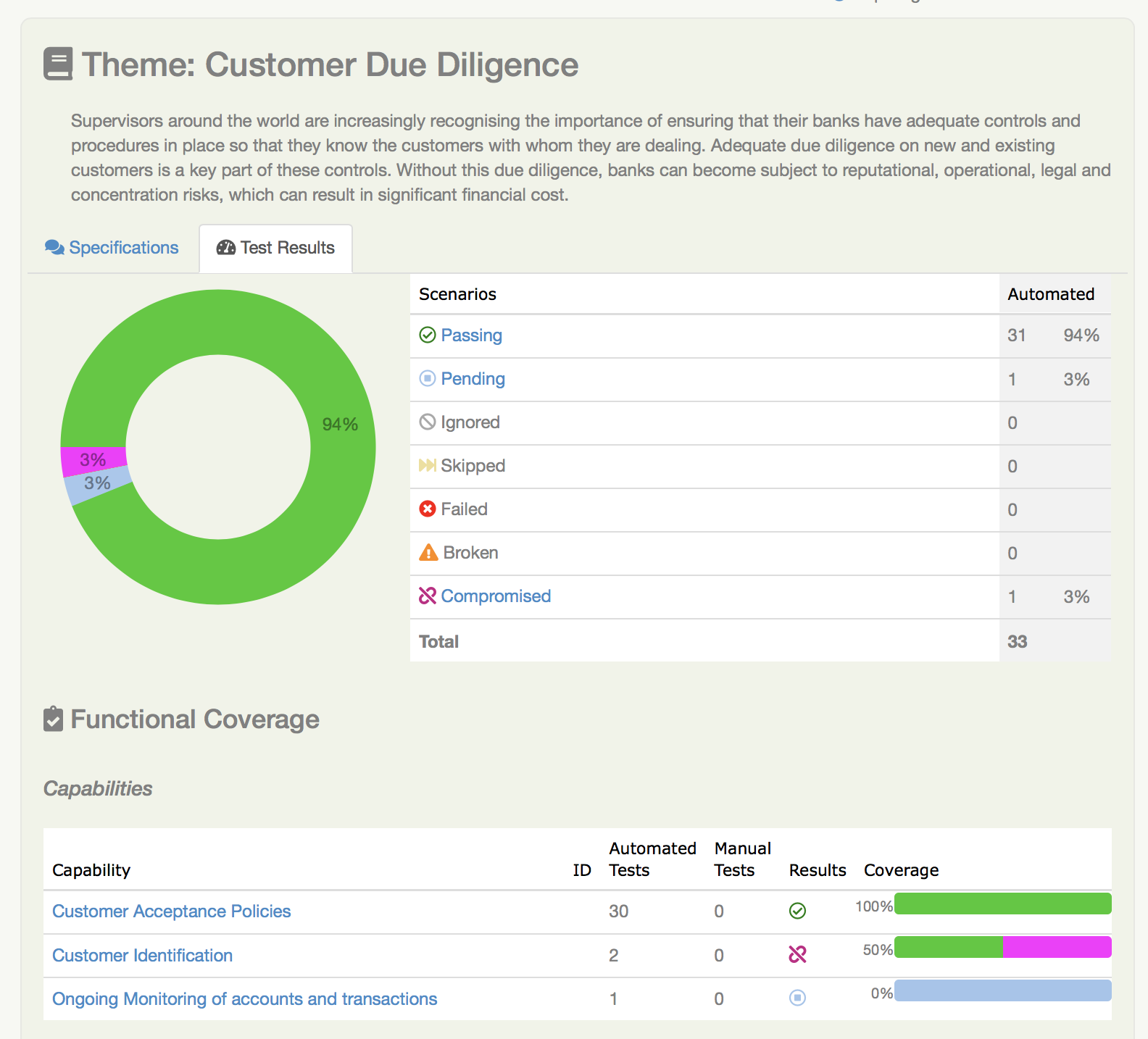
Por exemplo, na ilustração mostrada acima, o requisito de alto nível Customer Due Diligence tem três requisitos filhos:
- Customer Acceptance Policies
- Customer Identification, e
- Ongoing Monitoring
A visualização de cobertura funcional mostra o detalhamento dos resultados dos testes para cada um desses requisitos filhos. Esta é uma forma útil de ter uma ideia da estabilidade ou prontidão para release de diferentes partes de uma aplicação.
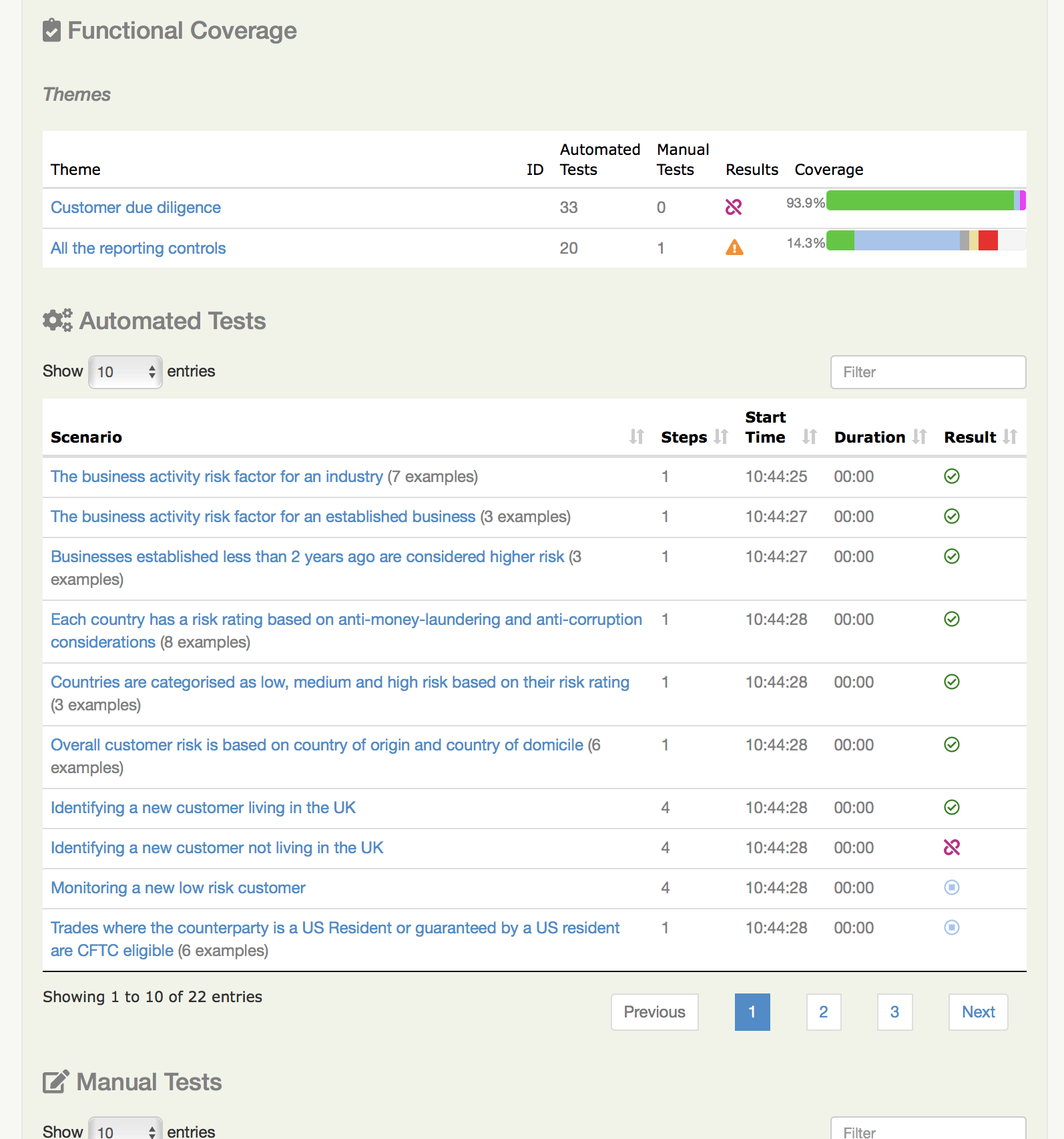
Resultados dos Testes
Na parte inferior da aba Resultados dos Testes, você encontrará os resultados reais dos testes - a lista de todos os testes, automatizados e manuais, que foram executados para este requisito.
Visões Gerais de Feature
Feature são uma parte importante do modelo de documentação viva do Serenity. Feature correspondem ao conteúdo de um arquivo de feature no Cucumber, um arquivo de story no JBehave, ou um caso de teste no JUnit. Uma Feature representa uma peça coerente de funcionalidade que os clientes valorizam; como regra geral, uma Feature é algo que poderíamos implantar sozinho e os usuários ainda achariam útil.
Uma Feature contém um conjunto de critérios de aceitação, cenários automatizados que demonstram e verificam como a Feature funciona. Mas frequentemente os critérios de aceitação não são suficientes por si só para explicar completamente o que uma Feature faz. Precisamos de algumas informações extras, que fornecemos no topo do arquivo de feature ou story. Por exemplo, no seguinte arquivo de feature, damos algum contexto de negócio adicional sobre a Feature Business Activities antes de mergulhar em cenários individuais:
Feature: Business Activities
Algumas atividades comerciais são consideradas mais propensas a riscos do que outras,
e certos clientes e entidades podem representar riscos específicos.
Scenario Outline: O fator de risco de atividade comercial para uma indústria
O fator de risco da indústria é um valor de 0 a 10.
When um cliente trabalha em <Business Category>
Then seu fator de risco de atividade comercial base deve ser <Risk Factor>
Examples:
| Business Category | Risk Factor |
| Casino | 10 |
| Precious Metals Exchange | 9 |
| Currency Exchange | 9 |
| Jewellery Store | 8 |
| Convenience Store | 7 |
| Real Estate Broker | 6 |
| Software Development | 3 |
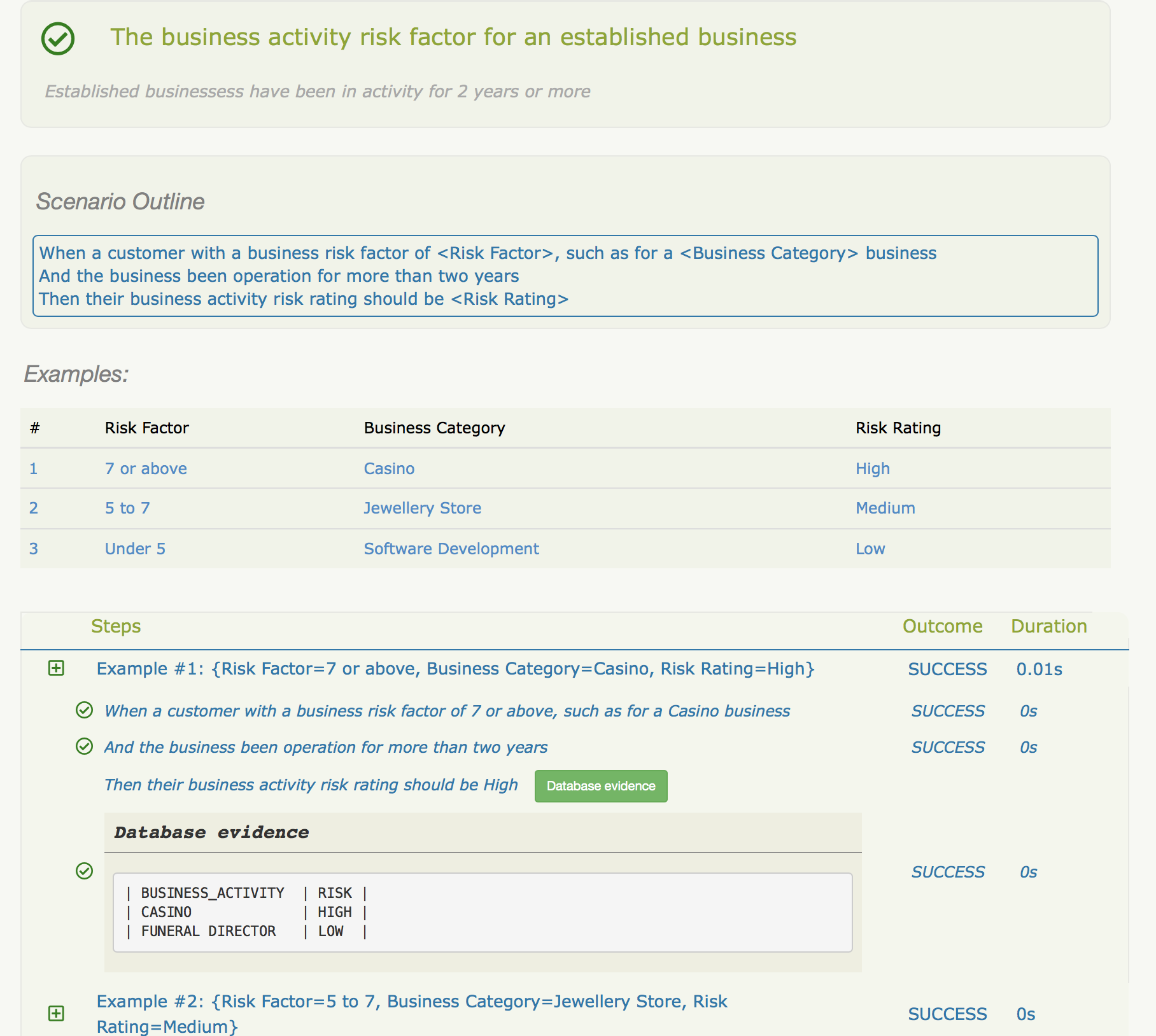
Scenario Outline: O fator de risco de atividade comercial para um negócio estabelecido
Negócios estabelecidos estão em atividade há 2 anos ou mais
When um cliente com um fator de risco comercial de <Risk Factor>, como para um negócio <Business Category>
And o negócio está em operação há mais de dois anos
Then sua classificação de risco de atividade comercial deve ser <Risk Rating>
Examples:
| Risk Factor | Business Category | Risk Rating |
| 7 or above | Casino | High |
| 5 to 7 | Jewellery Store | Medium |
| Under 5 | Software Development | Low |
...
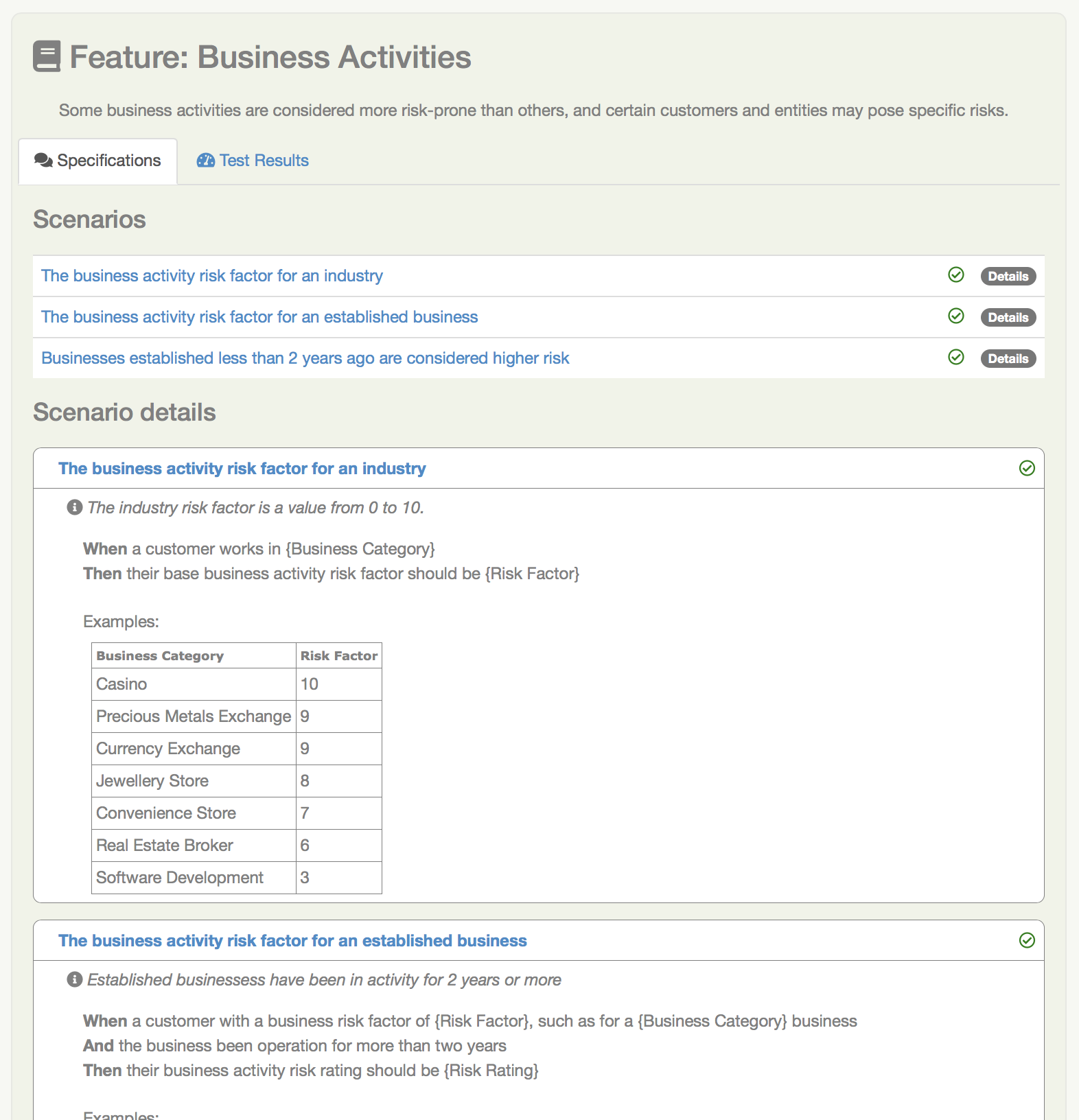
A página de requisitos para esta Feature é mostrada em A página de requisitos para uma Feature.
Aqui vemos o texto introdutório do topo do arquivo de feature, a lista de cenários (ou critérios de aceitação) definidos para esta Feature, e uma descrição detalhada de cada cenário. Ícones indicam se um cenário passou ou falhou, e se você clicar na barra de título de um dos cenários, irá para a página de resultados do teste para esse cenário.
A página de requisitos para uma Feature
Documentação de Feature Aprimorada
Quando você usa o Serenity com Cucumber, pode transformar esta visão geral de Feature em um documento vivo rico que mistura regras de negócio com exemplos e cenários extraídos dos testes de aceitação. Isso permite que você projete uma visão geral de requisitos que product owners e stakeholders podem revisar rapidamente e facilmente, enquanto ainda mantém os detalhes à mão se quiserem saber mais.
A documentação de Feature aprimorada atualmente é suportada apenas para Cucumber.
Por exemplo, poderíamos melhorar a visão geral da Feature Business Activities incorporando as tabelas (mas não os textos "Given..When..Then" que essencialmente atuam como fixtures de texto neste caso). Para fazer isso, usamos a tag {Examples} junto com o nome do Scenario Outline que queremos usar:
Feature: Business Activities
Algumas atividades comerciais são consideradas mais propensas a riscos do que outras,
e certos clientes e entidades podem representar riscos específicos.
O fator de risco de atividade comercial para uma indústria é determinado pelo risco potencial que apresentam ao banco. Por exemplo:
{Examples} The business activity risk factor for an industry
Quando o relatório é gerado, o Serenity incluirá a tabela de exemplos do cenário The business activity risk factor for an industry na descrição da Feature (veja Visão Geral da Feature com Tabelas de Exemplos).
Visão Geral da Feature com Tabelas de Exemplos
Se os testes para esta tabela foram executados, o resultado para cada linha será indicado na tabela.
A forma padrão (usando a tag {Examples}) pegará apenas a tabela de exemplos do Scenario Outline; se você quiser que o título também seja exibido, pode usar a tag {Examples!WithTitle} em vez disso.
Cenários são geralmente muito granulares para o resumo da Feature, e é melhor deixá-los para a seção detalhada mais abaixo na página. No entanto, às vezes faz sentido incluir um ou dois cenários no resumo. Você pode fazer isso usando a tag {Scenario}. Isso funciona tanto para cenários quanto para Scenario Outline.
Adicionando evidências adicionais
Às vezes, os resultados dos testes automatizados sozinhos não são suficientes para satisfazer stakeholders ou auditores. Precisamos ser capazes de adicionar alguma prova extra de que nossa aplicação funciona como descrito.
No Serenity, você pode adicionar evidências na forma de uma String ou do conteúdo de um arquivo. Por exemplo, você pode gravar os resultados de uma consulta SQL para demonstrar que um banco de dados contém os resultados esperados, ou gravar a versão completa de um relatório XML gerado quando você faz asserções apenas em alguns campos-chave.
Você pode fazer isso usando o método Serenity.recordReportData():
sqlQueryResult = ...
Serenity.recordReportData().withTitle("Database evidence").andContents(sqlQueryResult);
Este método permite gravar dados de uma String ou de um arquivo. Para obter dados de um arquivo, use o método fromFile():
Path report = ...
Serenity.recordReportData().withTitle("Generated Report").fromFile(report);
Em ambos os casos, esses dados são gravados com o teste, e aparecem nos resultados do teste:
Estruturas Comuns de Requisitos
A organização exata varia de projeto para projeto, mas algumas estruturas comuns incluem:
- Capacidades > Features
- Capacidades > Features > Stories
- Objetivos > Capacidades > Features
- Epics > Stories
- Temas > Epics > Stories
Uma hierarquia de requisitos de dois níveis funciona bem para a maioria dos projetos. Um projeto pequeno (por exemplo, um micro-serviço) pode precisar apenas de uma lista curta de features. Apenas projetos muito grandes ou complexos normalmente precisariam de três ou mais níveis.
Objetivos, Capacidades e Features
O objetivo de qualquer projeto de software é ajudar nossos stakeholders a alcançar seus objetivos fornecendo-lhes capacidades. No BDD, uma Capacidade é algo que permite aos usuários fazer algo que não podiam fazer anteriormente, ou fazer algo que podiam fazer anteriormente, mas fazer de forma mais eficiente. Uma capacidade é agnóstica em relação à tecnologia: ela não se compromete com uma solução ou implementação particular. Um exemplo de capacidade pode ser a habilidade de pagar online com cartão de crédito.
Uma Feature é uma solução ou implementação concreta que entrega uma capacidade. Algumas features possíveis que entregam a capacidade que mencionamos anteriormente podem ser pagar via PayPal, via Stripe ou pagar integrando com uma plataforma de banco comerciante.
Temas e Epics
No Scrum, um Epic é simplesmente uma grande história de usuário, uma que não pode ser entregue em um sprint. Um Tema é apenas outra forma de agrupar Histórias de Usuário relacionadas, embora muitas equipes usem Temas como grupos de epics relacionados. (Outra forma de implementar a ideia original de temas no Serenity BDD é usar tags).
Histórias de Usuário
Histórias de Usuário são comumente usadas no Agile como uma forma de organizar o trabalho, mas nem sempre são muito úteis quando se trata de Documentação Viva. Isso porque elas refletem como uma funcionalidade foi dividida quando foi construída. Mas uma vez que uma funcionalidade é entregue, ninguém se importa como ela foi dividida durante a fase de desenvolvimento - tudo o que importa é o que foi entregue. É por isso que o Cucumber prefere agrupar cenários em Arquivos de Feature (que descrevem uma funcionalidade). Por essa razão, Histórias de Usuário são geralmente consideradas como não sendo uma ótima forma de estruturar documentação viva. (Observe que o JBehave ainda usa a convenção mais antiga de "Arquivos de Story", que eram destinados a conter os critérios de aceitação de uma determinada história).
Configurando sua estrutura de requisitos no Serenity BDD
Você pode configurar a forma como o Serenity nomeia os diferentes níveis na sua própria estrutura de requisitos usando a propriedade serenity.requirements.types. Por exemplo, se você quiser descrever seus requisitos em termos de temas, epics e stories, você adicionaria o seguinte ao seu arquivo de configuração do Serenity:
serenity.requirements.types=theme,epic,story
Se você não configurar este parâmetro, o Serenity decidirá por uma hierarquia padrão sensata. Esta hierarquia depende se você está usando JUnit, Cucumber ou JBehave, e da profundidade da sua hierarquia de requisitos:
| Framework de Teste | Hierarquia Padrão |
|---|---|
| JUnit | capability > feature > story |
| Cucumber | theme > capability > feature |
| JBehave | capability > feature > story |
A configuração de requisitos se aplica aos níveis de contêiner, não aos arquivos de feature ou story em si. Se você estiver usando Cucumber, arquivos de feature sempre serão representados como features. Se você estiver usando JBehave, arquivos de story sempre serão representados como stories.
Hierarquias de Requisitos para Testes JUnit
Muitas equipes escrevem testes de aceitação automatizados com Serenity BDD usando JUnit. O Screenplay Pattern em particular facilita escrever testes altamente manuteníveis usando uma DSL legível por negócio que produz excelente documentação viva.
Existem duas formas de definir a hierarquia de requisitos para testes JUnit:
Hierarquia Baseada em Pacotes
Os testes de aceitação JUnit podem ser organizados em uma estrutura de pacotes que reflita sua hierarquia de requisitos. Observe que isso significa que eles podem não refletir a estrutura de pacotes na sua aplicação, como geralmente é feito para testes unitários e de integração.
Uma hierarquia simples de dois níveis é ilustrada aqui:
com
└── acme
└── myapps
└── specs
├── multiple_todo_lists
├── sharing_lists
└── simple_todo_lists
├── AddingNewItems.java
├── DeletingItems.java
├── FilteringItemsByStatus.java
└── MarkingItemsAsComplete.java
Você precisa informar ao Serenity onde encontrar a hierarquia de requisitos na sua estrutura de pacotes, usando a propriedade serenity.test.root. Para o exemplo mostrado acima, o pacote raiz é com.acme.myapp.specs:
serenity.test.root=com.acme.myapp.specs
Neste caso, a documentação viva do Serenity tratará os casos de teste JUnit ("Adding New Items", "Deleting Items" etc.) como Stories, e os pacotes diretamente abaixo do pacote com.acme.myapp.specs ("Multiple Todo Lists", "Sharing Lists" etc.) como Features.
Hierarquia Baseada em Anotações
A partir do Serenity 5.3.1, você também pode definir a hierarquia de requisitos diretamente usando as anotações @Epic, @Feature e @Story nas suas classes de teste:
@Feature("Managing Todos")
@Story("Complete todo items")
class WhenCompletingTodosTest {
// ...
}
Isso cria uma hierarquia de requisitos baseada nos valores das anotações em vez da estrutura de pacotes. Consulte Requisitos Baseados em Anotações para um guia completo com exemplos.
Hierarquias de Requisitos para Cucumber
Quando você usa Cucumber, o Serenity espera que seus arquivos de feature sejam armazenados no diretório src/test/resources/features. Sua hierarquia de requisitos vai diretamente abaixo deste diretório:
src
└── test
└── resources
└── features
├── multiple_todo_lists
├── sharing_lists
└── simple_todo_lists
├── adding_new_items.feature
├── deleting_items.feature
├── filtering_items_by_status.feature
└── marking_items_as_complete.feature
Quando o Cucumber é usado com a configuração padrão, os arquivos de feature sempre representam Features, e os diretórios que contêm as features representam Capacidades. Uma Feature é tipicamente maior do que uma história de usuário, e pode conter os critérios de aceitação (cenários) de várias histórias de usuário.
Hierarquias de Requisitos para JBehave
Quando você usa JBehave, o Serenity espera que seus arquivos de Story sejam armazenados no diretório src/test/resources/stories. Sua hierarquia de requisitos vai diretamente abaixo deste diretório:
src
└── test
└── resources
└── stories
├── multiple_todo_lists
├── sharing_lists
└── simple_todo_lists
├── adding_new_items.story
├── deleting_items.feature
├── filtering_items_by_status.story
└── marking_items_as_complete.story
Por padrão, os arquivos de Story representam stories, e os diretórios acima deles são renderizados como Features.